2023

KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
2022
ARAH: Animatable Volume Rendering of Articulated Human SDFs
KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients
Hanselmann, N. R. K. C. K. B. A. G. A.
Proceedings 17th European Conference on Computer Vision (ECCV), 13698, pages: 335-352, (Editors: Avidan, S; Brostow, G; Cisse, M; Farinella, GM; Hassner, T), IEEE, ECCV, October 2022 (conference)
TensoRF: Tensorial Radiance Fields
PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
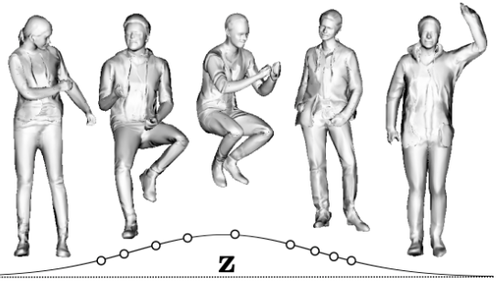
gDNA: Towards Generative Detailed Neural Avatars
Chen, X., Jiang, T., Song, J., Yang, J., Black, M. J., Geiger, A., Hilliges, O.
In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), pages: 204395-20405, IEEE, Piscataway, NJ, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), June 2022 (inproceedings)
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
2021
Projected GANs Converge Faster
CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
On the Frequency Bias of Generative Models
Schwarz, K., Liao, Y., Geiger, A.
In Advances in Neural Information Processing Systems 34, 22, pages: 18126-18136, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
ATISS: Autoregressive Transformers for Indoor Scene Synthesis
Paschalidou, D., Kar, A., Shugrina, M., Kreis, K., Geiger, A., Fidler, S.
In Advances in Neural Information Processing Systems 34, 15, pages: 12013-12026, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
MetaAvatar: Learning Animatable Clothed Human Models from Few Depth Images
Wang, S., Mihajlovic, M., Ma, Q., Geiger, A., Tang, S.
In Advances in Neural Information Processing Systems 34, 4, pages: 2810-2822, (Editors: Ranzato, M. and Beygelzimer, A. and Dauphin, Y. and Liang, P. S. and Wortman Vaughan, J.), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
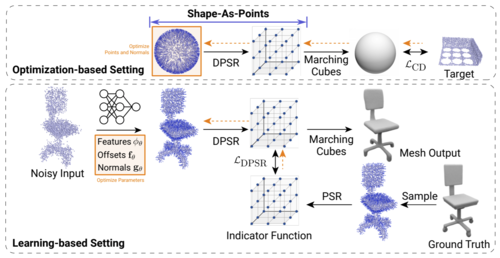
Shape As Points: A Differentiable Poisson Solver
Peng, S., Jiang, C. M., Liao, Y., Niemeyer, M., Pollefeys, M., Geiger, A.
In Advances in Neural Information Processing Systems 34, 16, pages: 13032-13044, (Editors: M. Ranzato and A. Beygelzimer and Y. Dauphin and P. S. Liang and J. Wortman Vaughan), Curran Associates, Inc., Red Hook, NY, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), December 2021 (inproceedings)
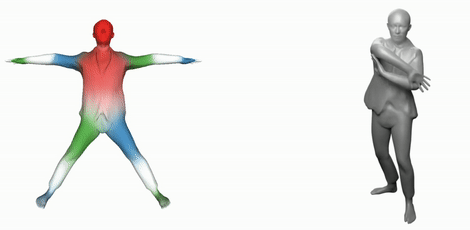
SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes
Chen, X., Zheng, Y., Black, M. J., Hilliges, O., Geiger, A.
In Proc. International Conference on Computer Vision (ICCV), pages: 11574-11584, IEEE, Piscataway, NJ, International Conference on Computer Vision 2021, October 2021 (inproceedings)
Learning Steering Kernels for Guided Depth Completion
Liu, L., Liao, Y., Wang, Y., Geiger, A., Liu, Y.
IEEE Transactions on Image Processing , 30, pages: 2850 - 2861, IEEE, February 2021 (article)

SMD-Nets: Stereo Mixture Density Networks
Tosi, F., Liao, Y., Schmitt, C., Geiger, A.
Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (article)
Zoomorphic Gestures for Communicating Cobot States
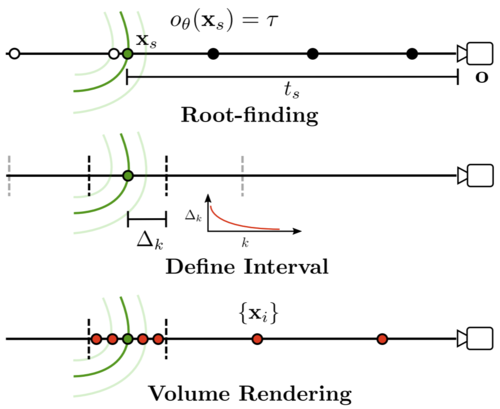
UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction
Oechsle, M., Peng, S., Geiger, A.
In International Conference on Computer Vision (ICCV), 2021 (inproceedings)
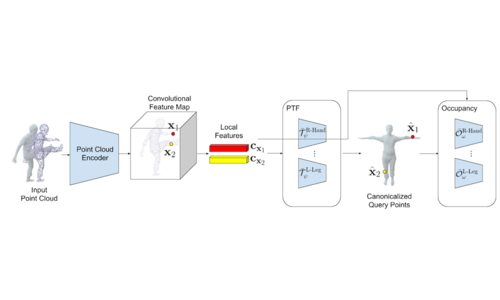
Locally Aware Piecewise Transformation Fields for 3D Human Mesh Registration
Wang, S., Geiger, A., Tang, S.
In Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (inproceedings)

SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation
Baur, S., Emmerichs, D., Moosmann, F., Pinggera, P., Ommer, B., Geiger, A.
In 2021 (inproceedings)

Counterfactual Generative Networks

Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
Paschalidou, D., Katharopoulos, A., Geiger, A., Fidler, S.
In Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (inproceedings)
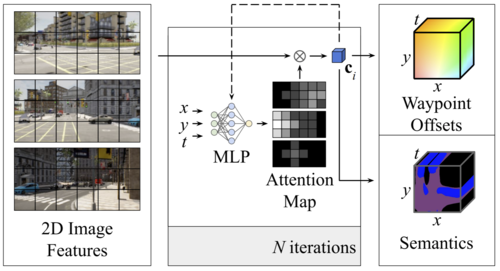
NEAT: Neural Attention Fields for End-to-End Autonomous Driving
Chitta, K., Prakash, A., Geiger, A.
In International Conference on Computer Vision (ICCV), 2021 (inproceedings)
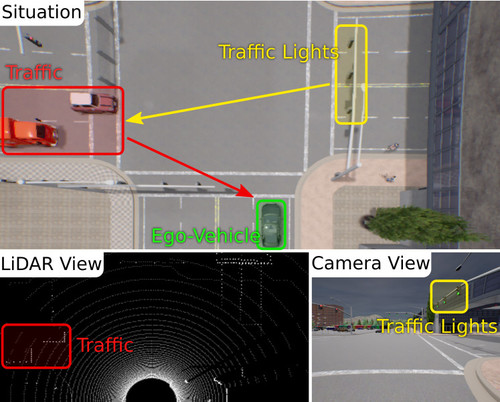
Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
Prakash, A., Chitta, K., Geiger, A.
In Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (inproceedings)
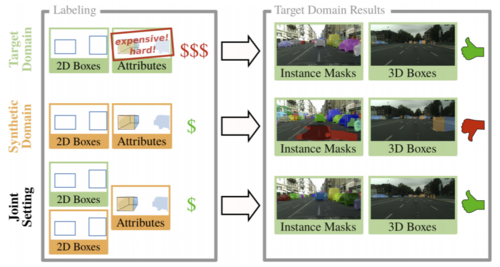
Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
Hanselmann, N., Schneider, N., Ortelt, B., Geiger, A.
In Intelligent Vehicles Symposium (IV), 2021 (inproceedings)
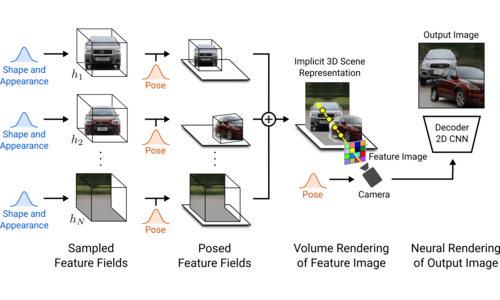
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
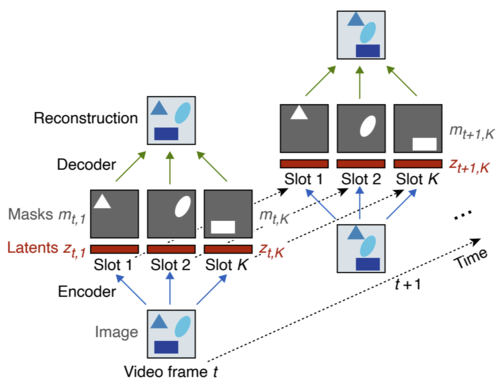
Benchmarking Unsupervised Object Representations for Video Sequences
Weis, M., Chitta, K., Sharma, Y., Brendel, W., Bethge, M., Geiger, A., Ecker, A.
Journal of Machine Learning Research (JMLR), 2021 (article)
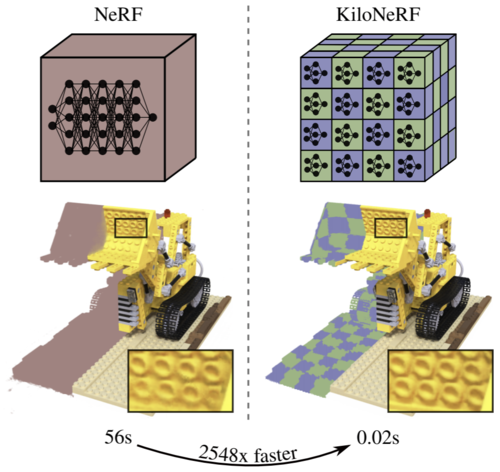
KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
Reiser, C., Peng, S., Liao, Y., Geiger, A.
In International Conference on Computer Vision (ICCV), 2021 (inproceedings)
2020

GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
Schwarz, K., Liao, Y., Niemeyer, M., Geiger, A.
In Advances in Neural Information Processing Systems 33, 25, pages: 20154-20166, (Editors: Larochelle , H. and Ranzato, M. and Hadsell , R. and Balcan , M. F. and Lin, H.), Curran Associates, Inc., Red Hook, NY, 34th Conference on Neural Information Processing Systems (NeurIPS 2020), December 2020 (inproceedings)

Label Efficient Visual Abstractions for Autonomous Driving
Behl, A., Chitta, K., Prakash, A., Ohn-Bar, E., Geiger, A.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, October 2020 (conference)
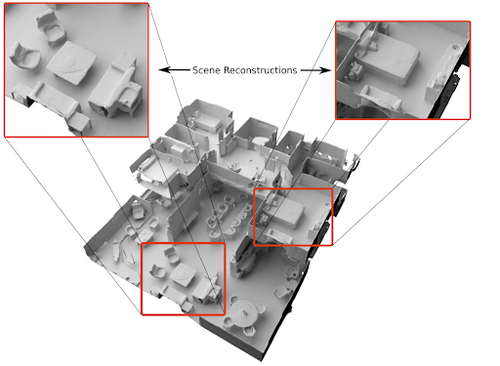
Convolutional Occupancy Networks
Peng, S., Niemeyer, M., Mescheder, L., Pollefeys, M., Geiger, A.
In Computer Vision – ECCV 2020, 3, pages: 523-540, Lecture Notes in Computer Science, 12348, (Editors: Vedaldi, Andrea and Bischof, Horst and Brox, Thomas and Frahm, Jan-Michael), Springer, Cham, 16th European Conference on Computer Vision (ECCV 2020), August 2020 (inproceedings)
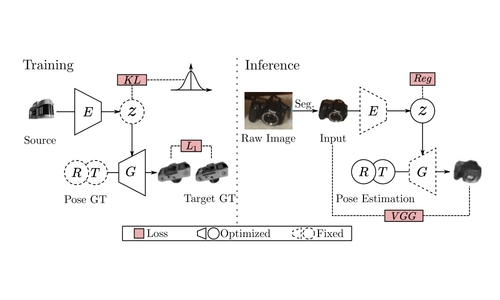
Category Level Object Pose Estimation via Neural Analysis-by-Synthesis
Chen, X., Dong, Z., Song, J., Geiger, A., Hilliges, O.
In Computer Vision – ECCV 2020, 26, pages: 139-156, Lecture Notes in Computer Science, 12371, (Editors: Vedaldi, Andrea and Bischof, Horst and Brox, Thomas and Frahm, Jan-Michael), Springer, Cham, 16th European Conference on Computer Vision (ECCV 2020) , August 2020 (inproceedings)
Self-Supervised Linear Motion Deblurring
Liu, P., Janai, J., Pollefeys, M., Sattler, T., Geiger, A.
IEEE Robotics and Automation Letters, 5(2):2475 - 2482, IEEE, April 2020 (article)
Scalable Active Learning for Object Detection
Haussmann, E. F. M. C. K. I. J. X. H. R. D. M. A. K. N. F. C. A. J. M.
Proceedings 31st IEEE Intelligent Vehicles Symposium (IV), pages: 1430-1435, IEEE, 31st IEEE Intelligent Vehicles Symposium (IV), 2020 (conference) Accepted
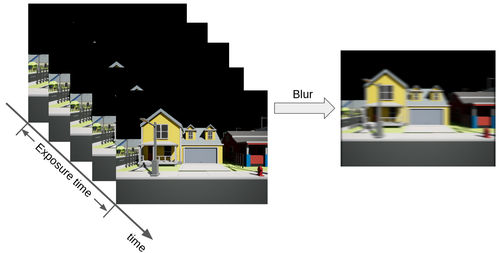
Self-supervised motion deblurring
Liu, P., Janai, J., Pollefeys, M., Sattler, T., Geiger, A.
IEEE Robotics and Automation Letters, 2020 (article)
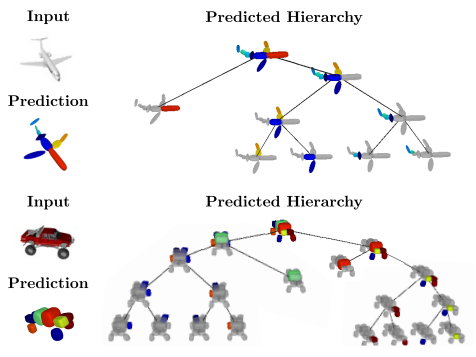
Learning Unsupervised Hierarchical Part Decomposition of 3D Objects from a Single RGB Image
Paschalidou, D., Gool, L., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)
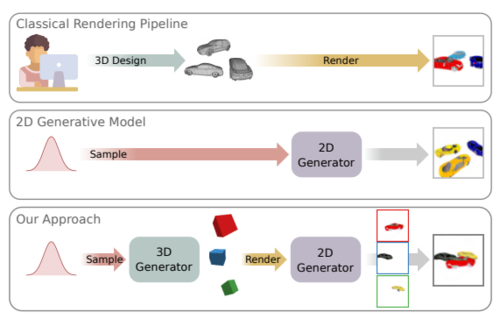
Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
Liao, Y., Schwarz, K., Mescheder, L., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)
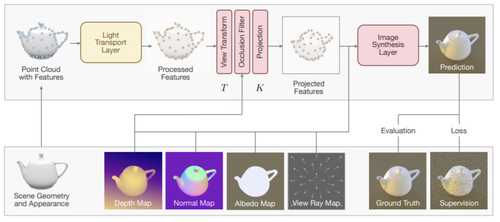
Learning Neural Light Transport
Sanzenbacher, P., Mescheder, L., Geiger, A.
Arxiv, 2020 (article)

Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving
Prakash, A., Behl, A., Ohn-Bar, E., Chitta, K., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)
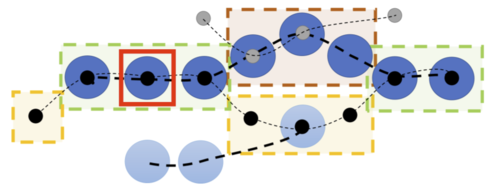
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixe, L., Leibe, B.
International Journal of Computer Vision, 129(2):548-578, 2020 (article)

On Joint Estimation of Pose, Geometry and svBRDF from a Handheld Scanner
Schmitt, C., Donne, S., Riegler, G., Koltun, V., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)
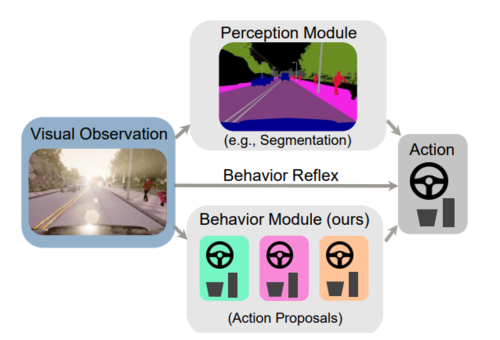
Learning Situational Driving
Ohn-Bar, E., Prakash, A., Behl, A., Chitta, K., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)

Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Hassan Alhaija, Siva Mustikovela, Varun Jampani, Justus Thies, Matthias Niessner, Andreas Geiger, Carsten Rother
In International Conference on 3D Vision (3DV), 2020 (inproceedings)

Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art
Janai, J., Güney, F., Behl, A., Geiger, A.
Arxiv, Foundations and Trends in Computer Graphics and Vision, 2020 (book)
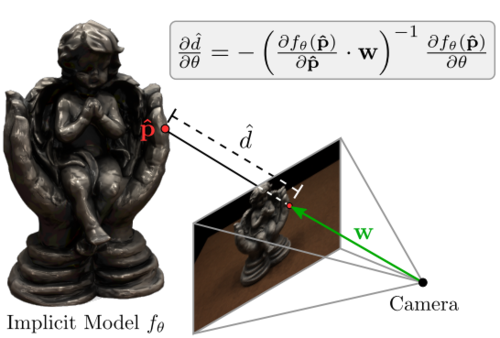
Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)
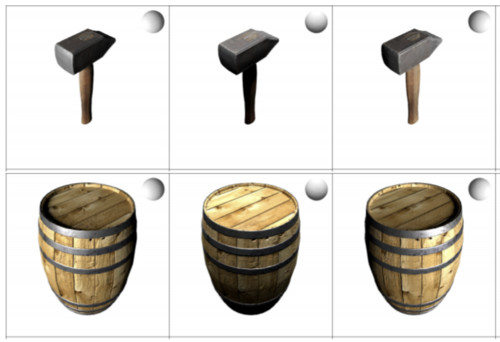
Learning Implicit Surface Light Fields
Oechsle, M., Niemeyer, M., Reiser, C., Mescheder, L., Strauss, T., Geiger, A.
In International Conference on 3D Vision (3DV), 2020 (inproceedings)
2019

Attacking Optical Flow
Ranjan, A., Janai, J., Geiger, A., Black, M. J.
In Proceedings International Conference on Computer Vision (ICCV), pages: 2404-2413, IEEE, 2019 IEEE/CVF International Conference on Computer Vision (ICCV), November 2019, ISSN: 2380-7504 (inproceedings)
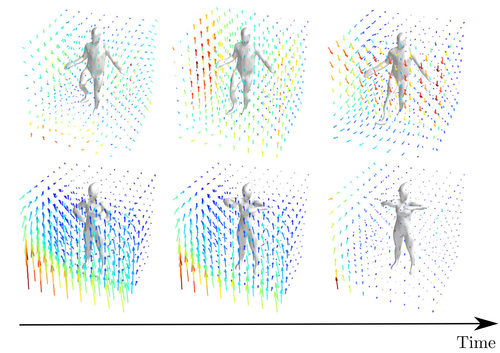
Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.
International Conference on Computer Vision, October 2019 (conference)
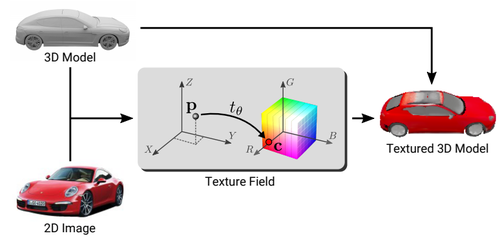
Texture Fields: Learning Texture Representations in Function Space
Oechsle, M., Mescheder, L., Niemeyer, M., Strauss, T., Geiger, A.
International Conference on Computer Vision, October 2019 (conference)